Wednesday, January 15, 2025
Building Enterprise Data Pipelines: The Medallion Architecture in Fintech
During the past summer (2025), I had the opportunity to work as a Data Engineer at a fintech company called Trepp. Trepp collects commercial real estate data, which it then transforms, models, and commercializes for downstream customers.
Because the true value of the company lies within its data, the engineering standards are incredibly high. While working there, we utilized a design pattern known as the Medallion Architecture. Essentially, this architecture divides the entire data pipeline into three distinct layers: Bronze, Silver, and Gold.
1. Bronze
Contains raw data exactly as it arrives from various sources.
2. Silver
Improves data quality and prepares it for analytics (cleansing and standardization).
3. Gold
Optimizes data for dashboards, business reporting, and machine learning models.
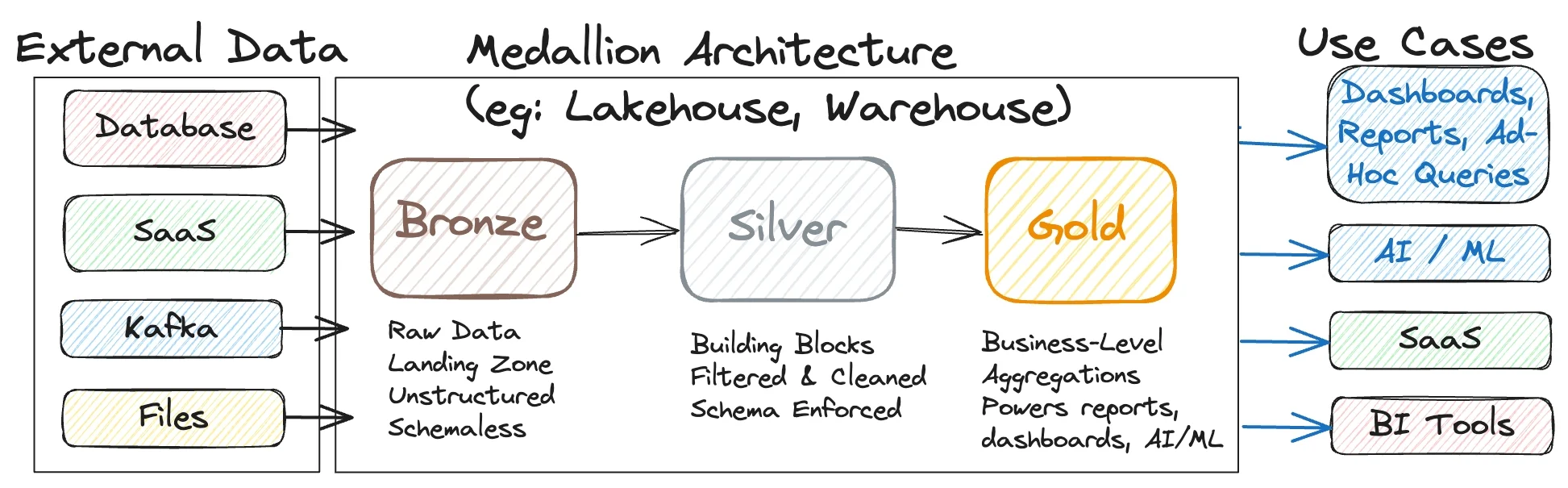
Why use the Medallion Architecture?
- Clear Lineage: Data progression is simple and logical, providing clear lineage and easier auditability.
- Modularity: You can treat the three layers almost like microservices; each layer operates independently, making it easier to plug in or remove specific components without breaking the whole chain.
The Trepp Implementation:
To make this clear from an enterprise perspective, let me explain how we applied this at Trepp using AWS Step Functions, Lambda, Apache Spark, and Apache Hudi.
1. Bronze Layer (Ingestion)
We used AWS Step Functions to orchestrate the workflow. The process kicked off with custom AWS Lambda scripts that fetched raw data from various external sources. We ingested this data exactly as-is into an S3 bucket, storing it as raw Parquet files. Storing it in Parquet at this stage compressed the data and made it efficient to read later, even though the content was still messy and unsorted.
2. Silver Layer (The Transformation)
This is where the heavy lifting happened. We used Apache Spark to read the raw Bronze data and apply transformations. One of the specific pipelines I worked on was an address standardization pipeline.
Why is this pipeline critical?
To a computer, "123 Main St." and "123 Main Street" look like completely different entities. The Silver layer standardizes these addresses into a universal format to ensure data integrity.
Once the data was cleaned, we stored it using Apache Hudi. An important feature of Hudi here was incremental ingestion. Instead of reprocessing the entire historical dataset every day, Hudi allowed us to process only the new or changed data coming from Bronze, significantly reducing our compute costs and processing time.
3. Gold Layer (Business Value)
Finally, for the Gold layer, we used Spark to transform the clean Hudi tables into reformatted models for specific use cases. This data is what actually powers the BI dashboards, Machine Learning models, and client-facing APIs. Because of standardization was done in Silver, the Gold layer queries are fast and reliable.
This is just a snapshot of how big companies handle data. Trepp runs a lot of different pipelines, but I think this one does the best job of showing how the Medallion Architecture actually works in the real world.